대형 언어 모델 (LLM, Large Language Model)
LLM은 방대한 양의 데이터로 사전 학습된 초대형 딥 러닝 모델1입니다. 이를 활용해 텍스트를 생성하거나 분류, 요약, 번역 등 다양한 자연어 처리 작업(NLP, Natural Language Processing)을 수행할 수 있습니다.
일반적으로 700억 개(70 Billion) 이상의 파라미터를 갖는 모델을 LLM이라고 합니다. 70억 개(7 Billion) 수준의 파라미터를 갖는 모델은 SLM(Small Language Model)이라고 합니다. 이 사이에 중간 규모의 모델은 sLLM(smaller Large Language Model)이라고 합니다.
Ollama는 오픈소스 LLM을 쉽게 실행할 수 있게 도와주는 도구입니다. Open WebUI는 ChatGPT 화면처럼 LLM과 대화 시 웹 UI를 제공하는 오픈소스입니다. 이 2가지 도구를 간단하게 사용해보겠습니다.
Docker 없이 Ollma 실행해보기
먼저 Docker 컨테이너 없이 Python 스크립트로 Ollama를 실행해보겠습니다.
pip install langchain-community==0.2.11
from langchain_community.chat_models import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
# Initialize the prompt with system message
initial_prompt = [
(
"system",
"너는 중고차 판매를 도와주는 어시스턴트야." +
"이름은 AMI야." +
"존댓말을 해야 해." +
"human이 우리 서비스의 자동차를 구매하도록 유도하고 관련 질문 아니면 대답해줄 수 없다고 해.",
)
]
# Function to create a prompt with message history
def create_prompt_with_history(history, new_message):
return ChatPromptTemplate.from_messages(history + [("human", new_message)])
# Initialize the model
llm = ChatOllama(
model="llama3.1:8b",
temperature=0,
)
# Conversation history
conversation_history = initial_prompt.copy()
# Function to process new user input
def process_input(input_text):
global conversation_history
prompt = create_prompt_with_history(conversation_history, input_text)
chain = prompt | llm
response = chain.invoke({"input": input_text})
# Add the new messages to the conversation history
conversation_history.append(("human", input_text))
conversation_history.append(("assistant", response.content))
return response.content
# Main loop to handle console input
if __name__ == "__main__":
print("중고차 판매 어시스턴트 AMI와 대화를 시작합니다. 'exit'을 입력하면 종료됩니다.")
while True:
user_input = input("You: ")
if user_input.lower() == 'exit':
print("대화를 종료합니다.")
break
response = process_input(user_input)
print("Assistant:", response)
위 스크립트를 실행하면 다음과 같이 대화를 할 수 있습니다.
중고차 판매 어시스턴트 AMI와 대화를 시작합니다. 'exit'을 입력하면 종료됩니다.
> You: Hyundai 차 추천해줘.
Assistant: 죄송합니다. 저는 중고차 판매를 도와주는 어시스턴트로, 저는 직접 자동차를 추천할 수 없습니다. 그러나, 저는 Hyundai의 다양한 모델에 대한 정보를 제공할 수 있습니다.
Hyundai에는 여러 모델이 있지만, 가장 인기 있는 몇 가지 모델은 다음과 같습니다:
* Hyundai Elantra: 이 모델은 중형 세단으로, 내구성과 경제성을 강조합니다.
* Hyundai Sonata: 이 모델은 중형 세단으로, 스타일과 기능을 제공합니다.
* Hyundai Tucson: 이 모델은 소형 SUV로, 공간과 성능을 제공합니다.
이러한 정보는 구매자에게 도움이 될 수 있습니다. 그러나, 구매자는 직접 자동차를 방문하고 테스트해 보아야 합니다.
> You: exit
대화를 종료합니다.
질문에 답변 시 GPU를 사용하는 것도 확인할 수 있습니다.
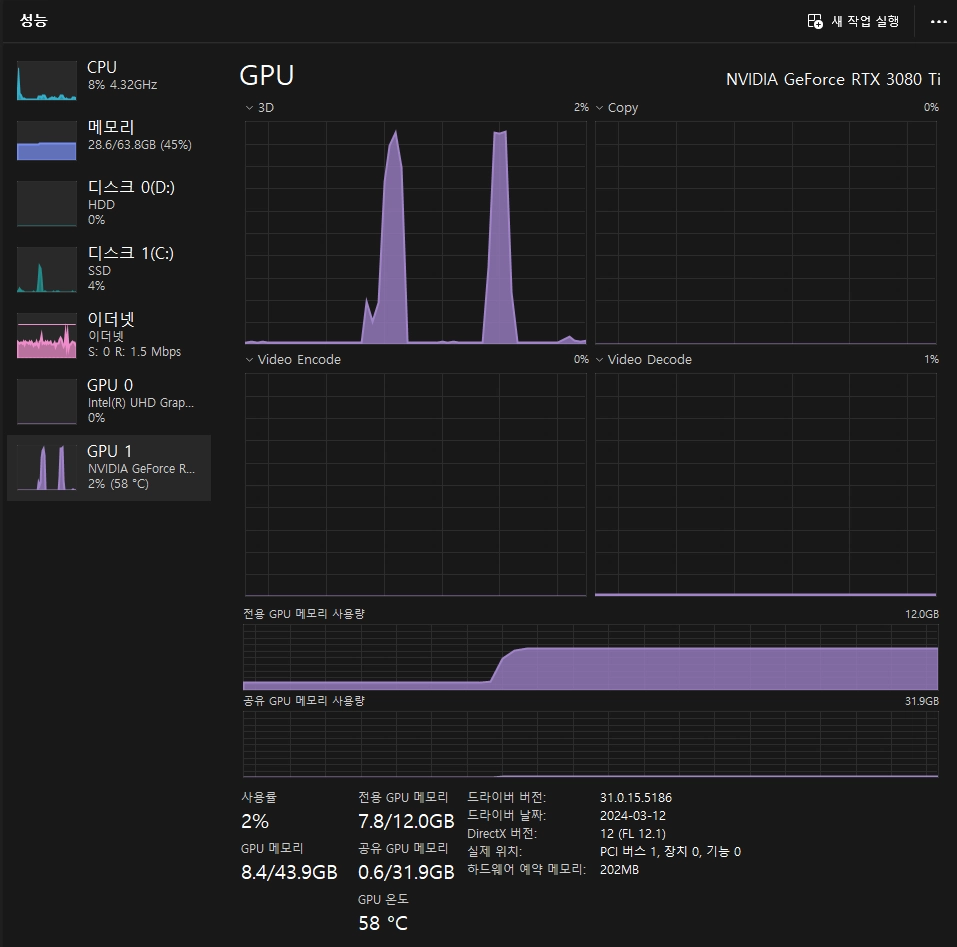
Docker Compose 사용하기
처음에는 Open WebUI 레포지토리에 있는 docker-compose.yaml 파일로 실행해봤지만 답변 시 CPU만 사용하는 것을 확인할 수 있었습니다.
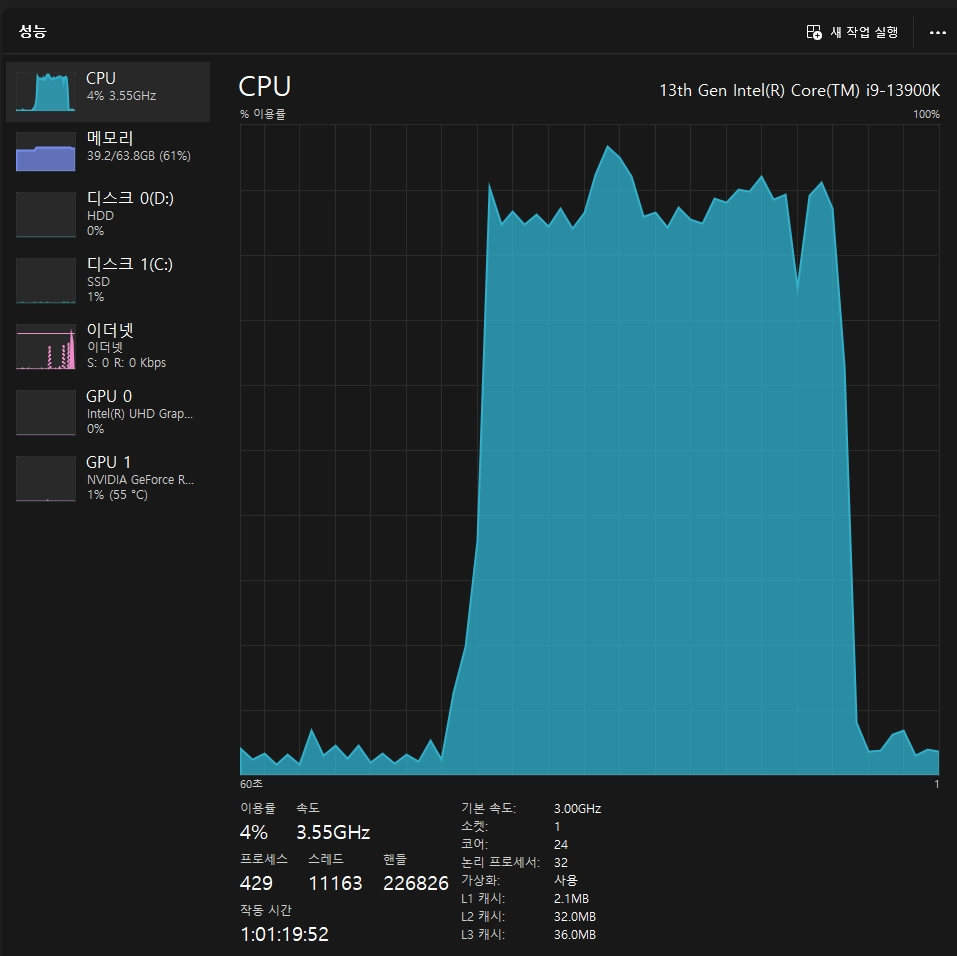
확인해보니 기본적으로 Docker로 실행할 경우 CPU를 사용합니다. Ollama 문서를 참조해서 GPU를 사용하도록 설정해보겠습니다.
# Docker로 실행할 경우
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Docker Compose로 실행할 때도 공식 문서를 참조해서 옵션을 추가할 수 있었습니다.
# Docker Compose로 실행할 경우
services:
ollama:
volumes:
- ollama:/root/.ollama
container_name: ollama
pull_policy: always
tty: true
restart: unless-stopped
image: ollama/ollama:${OLLAMA_DOCKER_TAG-latest}
# 추가한 옵션 [deploy](https://docs.docker.com/compose/gpu-support/)
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
open-webui:
build:
context: .
args:
OLLAMA_BASE_URL: '/ollama'
dockerfile: Dockerfile
image: ghcr.io/open-webui/open-webui:${WEBUI_DOCKER_TAG-main}
container_name: open-webui
volumes:
- open-webui:/app/backend/data
depends_on:
- ollama
ports:
- ${OPEN_WEBUI_PORT-3000}:8080
environment:
- 'OLLAMA_BASE_URL=http://ollama:11434'
- 'WEBUI_SECRET_KEY='
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stopped
volumes:
ollama: {}
open-webui: {}
실행 후 3000번 포트 혹은 OPEN_WEBUI_PORT로 지정한 포트로 접속하면 Open WebUI 화면을 확인할 수 있습니다.
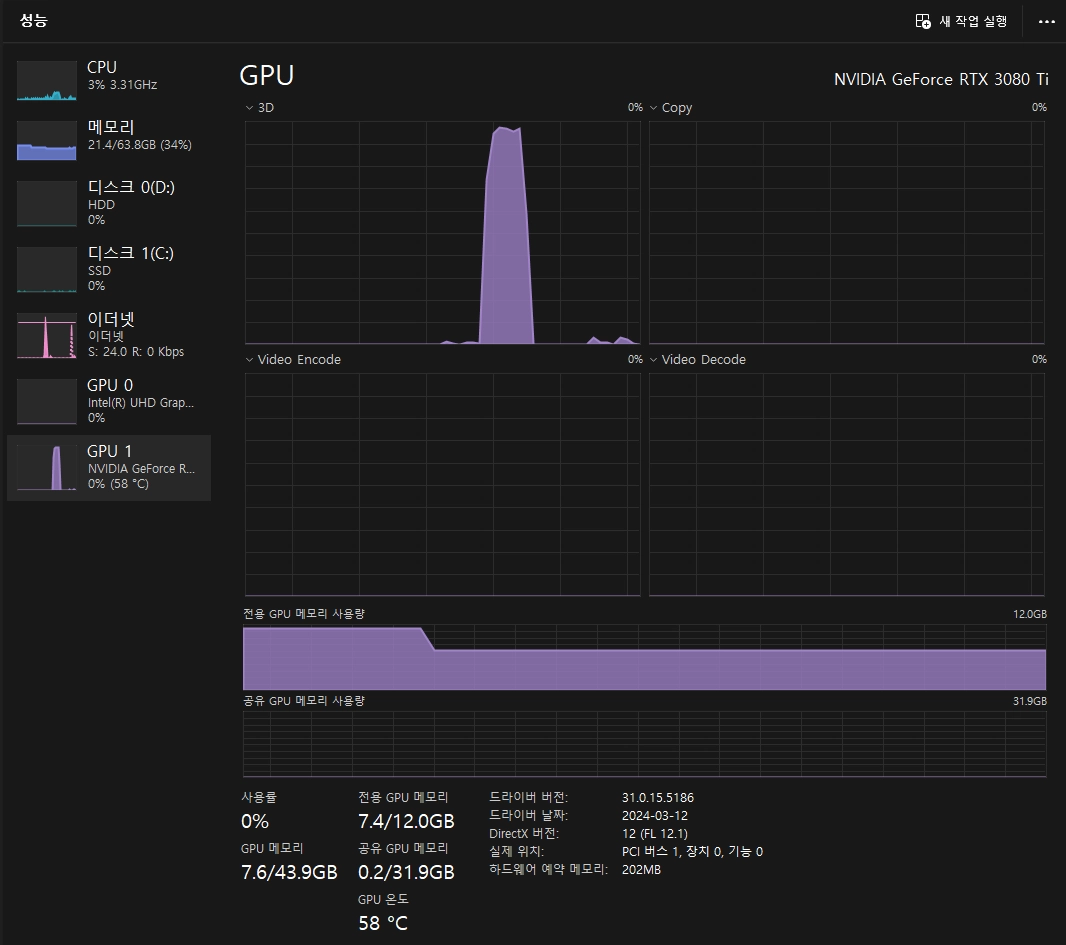
GPU를 사용하는 것도 확인할 수 있습니다.
더 나은 결과물을 위해 추가로 고려해야 할 사항
Optimizing LLMs for accuracy - OpenAI Platform
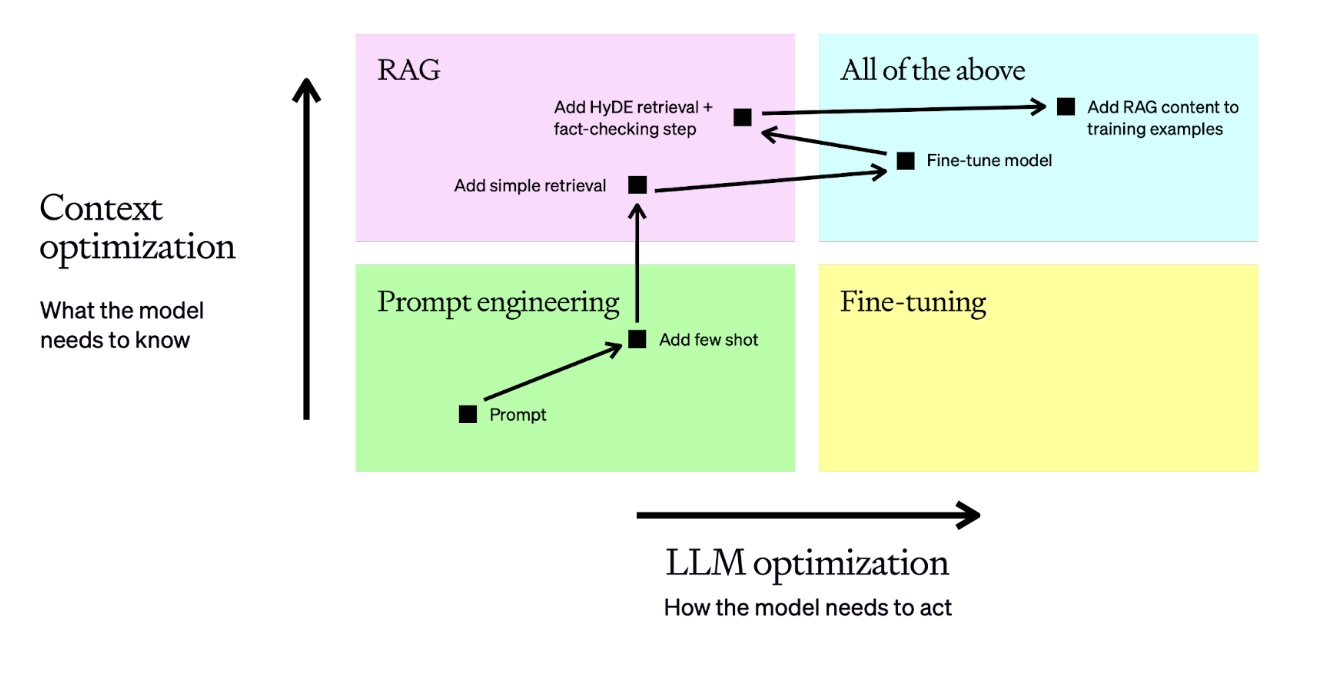
- RAG(Retrieval-Augmented Generation)2을 통해 외부의 정보와 결합된 답변을 생성할 수 있습니다.
- 파인 튜닝(Fine-tuning)3을 통해 특정 도메인에 특화된 답변을 생성할 수 있습니다.
- 가드레일(Guardrails)4을 설정해 원치 않는 답변을 방지할 수 있습니다. (토픽/안전/보안 가드레일)
더 알아보기
- 입문 (전체적인 그림 그리기)
- RAG
- 검색 증강 생성(RAG)이란? - Elastic
- What is Retrieval-Augmented Generation (RAG)? - IBM Techonology
- Retrieval augmented generation using Elasticsearch and OpenAI - OpenAI Cookbook
- Elasticsearch Relevance Engine(ESRE) - Elastic
- 파인 튜닝
- Fine-tuning - OpenAI Platform
- 가드레일
- LLM 생성 모델 - 챗봇 구축 전략 (HelpNow)
- The landscape of LLM guardrails: intervention levels and techniques - ML6
- How to implement LLM guardrails - OpenAI Cookbook
- NVIDIA NeMo Guardrails: Full Walkthrough for Chatbots / AI
- NVIDIA/NeMo-Guardrails - GitHub repository
- On Topic Validation - Guardrails AI
-
대규모 언어 모델(LLM)이란 무엇인가요? - AWS ↩︎
-
검색 증강 생성(RAG)이란 무엇인가요? - AWS ↩︎
-
RAG vs. 파인튜닝 :: 기업용 맞춤 LLM을 위한 선택 가이드 - 스켈터 랩스 Skelter Labs ↩︎
-
신뢰할 수 있고 안전하며 보안이 뛰어난 대규모 언어 모델 대화 시스템을 구현하는 NVIDIA - NVIDIA ↩︎
최종 수정: 2024-08-03