개요
저희 팀에서 구독 중인 Oracle DBMS의 라이센스는 Standard Edition 2의 Processor 라이센스(이하 SE2)입니다. 이 라이센스는 프로세서 최대 2개, CPU Threads 최대 16개까지 사용할 수 있습니다. 만약 트래픽이 많지 않다면 이 정도 사양으로도 충분하겠지만, 트래픽이 많아지거나 DB를 비효율적으로 사용하게 되면 성능 저하가 발생할 수 있습니다. 하지만 우리는 성능 저하가 발생했을 때 이를 진단할 방법이 없었습니다. SE2의 경우 AWR(Automatic Workload Repository), ASH(Active Session History)와 같은 Oracle Diagnostics Pack을 사용할 수 없습니다.
DB 진단 도구가 필요합니다
연산이 오래 걸리는 쿼리의 경우 SQL을 튜닝해서 해결했습니다. 검색 기능의 경우 Elasticsearch에 데이터를 연동해서 Inverted index로 성능을 향상시켰습니다.
하지만 어떤 경우에는 성능 저하가 발생했을 때 관련 애플리케이션 전체가 도미노처럼 쓰러졌습니다. Oracle DBMS의 세션 정보는 실시간으로만 조회할 수 있었기 때문에 지나간 정보를 확인할 수 없었습니다. 이를 해결하기 위해 세션 정보를 수집하는 스크립트를 작성하고, 시각화할 필요가 있었습니다.
Oracle DBMS의 현재 세션 정보들을 확인할 수 있는 동적 성능 뷰(V$SESSION)에서 세션 정보를 수집하기 위해 사용한 SQL은 다음과 같습니다.
SELECT *
FROM (SELECT sess.sid,
sess.serial#,
ROUND(sess.wait_time_micro / 1000, 2) wait_time_millis,
ROUND(sess.time_since_last_wait_micro / 1000, 2) time_since_last_wait_millis,
CASE
WHEN sess.status = 'ACTIVE'
THEN sess.last_call_et
ELSE 0
END active_elapsed_time_secs,
sess.state,
sess.event,
sess.username,
sess.osuser,
sess.machine,
sess.program,
sess.type,
sess.sql_child_number,
sess.sql_exec_id,
sess.sql_exec_start,
sess.sql_id,
(SELECT sql.sql_fulltext
FROM v$sql sql
WHERE sess.sql_id = sql.sql_id
FETCH FIRST 1 ROWS ONLY) sql_fulltext,
sess.prev_exec_id,
sess.prev_exec_start,
sess.prev_sql_id,
(SELECT sql.sql_fulltext
FROM v$sql sql
WHERE sess.prev_sql_id = sql.sql_id
FETCH FIRST 1 ROWS ONLY) prev_sql_fulltext,
blocking_session
FROM v$session sess
WHERE sess.username != 'SYS'
ORDER BY logon_time DESC)
WHERE (wait_time_millis > 0 OR time_since_last_wait_millis > 0)
/*아래는 DBMS 시스템 쿼리를 제외시키기 위함*/
AND dbms_lob.compare(prev_sql_fulltext, 'update user$ set spare6=DECODE(to_char(:2, ''YYYY-MM-DD''), ''0000-00-00'', to_date(NULL), :2) where user#=:1') != 0
AND dbms_lob.compare(prev_sql_fulltext, 'BEGIN :1 := sys.kupc$que_int.get_status(:2, :3); END;') != 0
AND dbms_lob.compare(prev_sql_fulltext, 'UPDATE "SYSTEM"."SYS_EXPORT_SCHEMA_01" SET value_n = :1 WHERE process_order = :2') != 0
AND dbms_lob.compare(sql_fulltext, 'BEGIN :1 := sys.kupc$que_int.receive(:2); END;') != 0
중점적으로 수집하고 싶었던 데이터는 Wait Event와 SQL Full Text였습니다. 이를 Elasticsearch에 저장하려면 식별자가 필요했습니다.
id = f"{prev_exec_id}-{prev_sql_id}-{unix_epoch_time(prev_exec_start)}"
먼저 고려했던 식별자는 sql_exec_id와 sql_id입니다.
하지만 대기 상태라면 sql_exec_id는 NULL이기 때문에 prev_exec_id와 prev_sql_id를 선택했습니다.
어느 정도 데이터가 쌓이고 살펴보니 prev_exec_id와 prev_sql_id 만으로도 충분히 식별되었습니다.
하지만 만에 하나를 위해 prev_exec_start도 추가했습니다.
누적된 데이터를 Kibana로 시각화하면 다음과 같습니다.
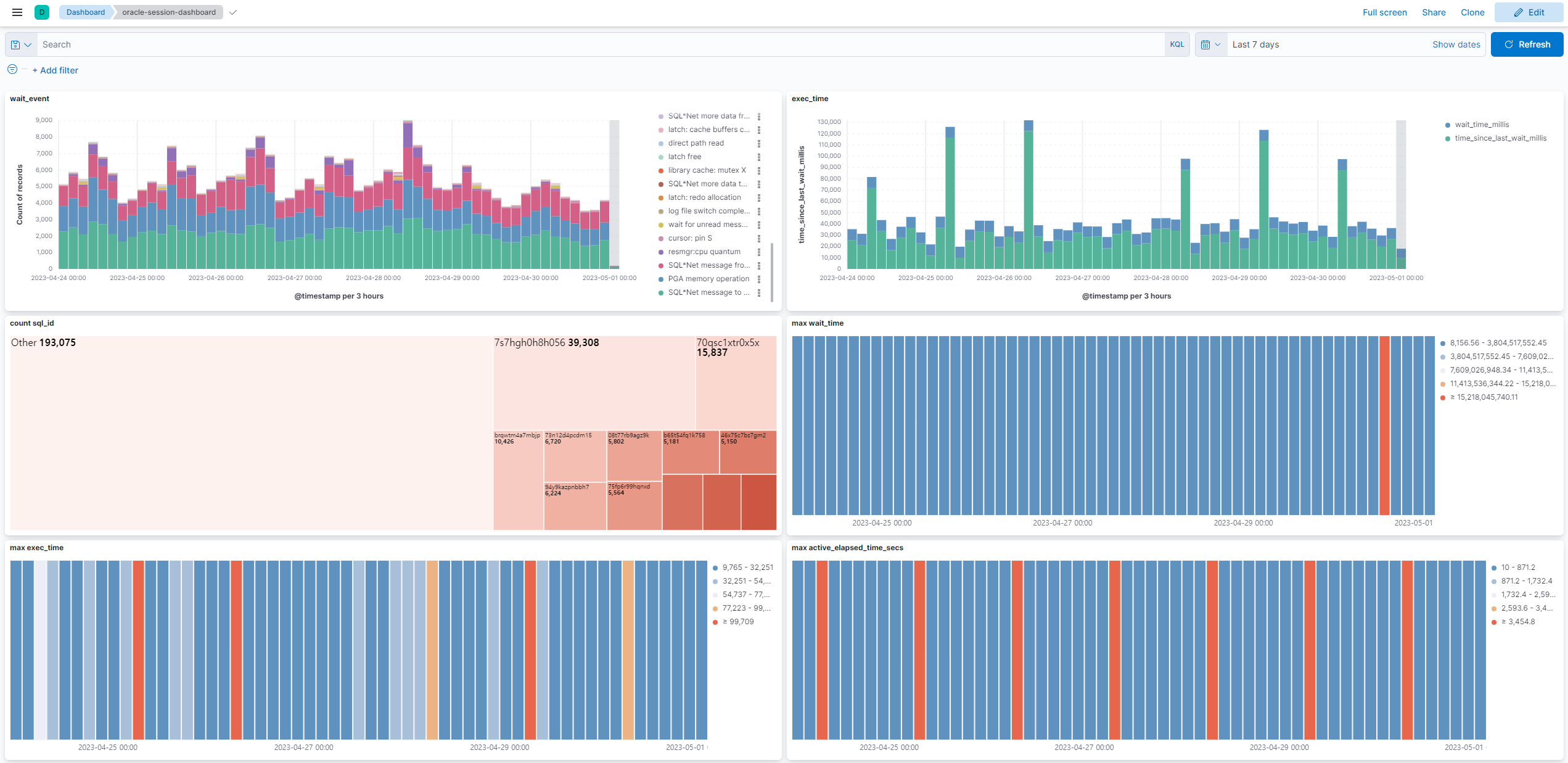
사용 사례
DBMS 성능 저하가 발생한 뒤 확인하는 Wait Event와 SQL은 후행 지표입니다. 메트릭을 모니터링하고 알람을 줄 수 있는 지표가 아닙니다. 이런 지표가 필요하다면 Prometheus나 Datadog을 사용합니다. 우리가 처음 원했던 건 성능 저하가 발생했을 때 이를 진단할 방법이었습니다.
resmgr:cpu quantum
세션이 CPU 자원을 할당받기 위해 대기하는 이벤트1입니다. Oracle DBMS에 Resource Manager(resmgr)가 활성화되어 있고 CPU 사용량이 제한(throttling)되어 있을 때 발생합니다.
먼저 IDC에서 CPU 사용량 알람이 지속적으로 발생했습니다.
대시보드를 확인해보니 Wait Event resmgr:cpu quantum이 다수 발생했습니다.
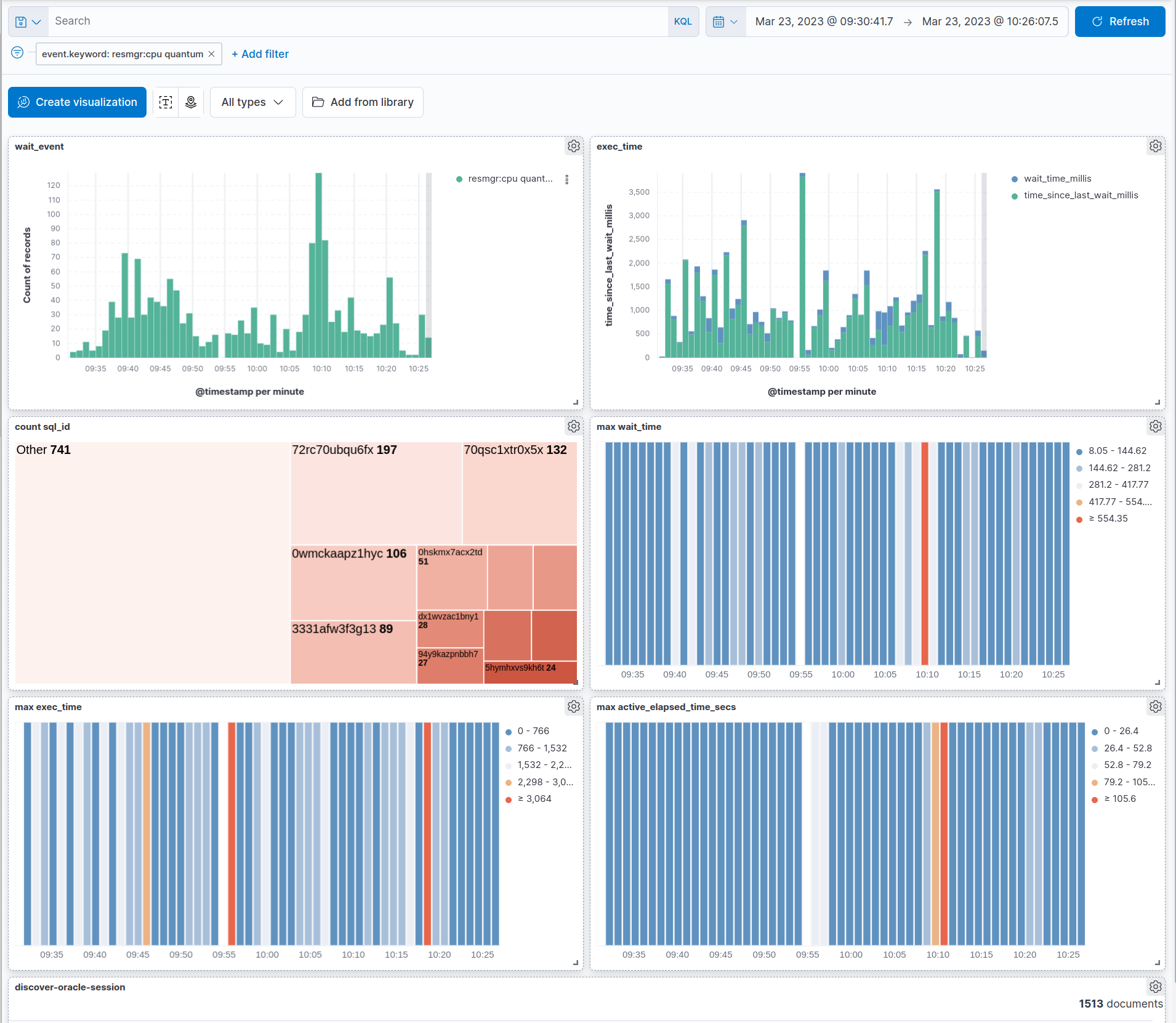
해당 Wait Event가 발생한 SQL의 Execution Plan을 확인해보니, 실행 시간은 빠르지만 CPU cost가 높은 것이 집중적으로 실행되었습니다. SE2는 리소스가 제한된 만큼 리소스를 효율적으로 사용하는 것이 속도만큼 중요했습니다.
이는 Execution Plan을 확인하면서 SQL을 튜닝하는 방법으로 해결했습니다. 주로 인덱스를 변경하거나 캐싱하는 방법으로 해결했습니다. 불필요한 쿼리도 제거했습니다.
enq: TX - row lock contention
여러 개의 트랜잭션이 동시에 같은 데이터 블록에 접근하려고 할 때 발생하는 이벤트2입니다.
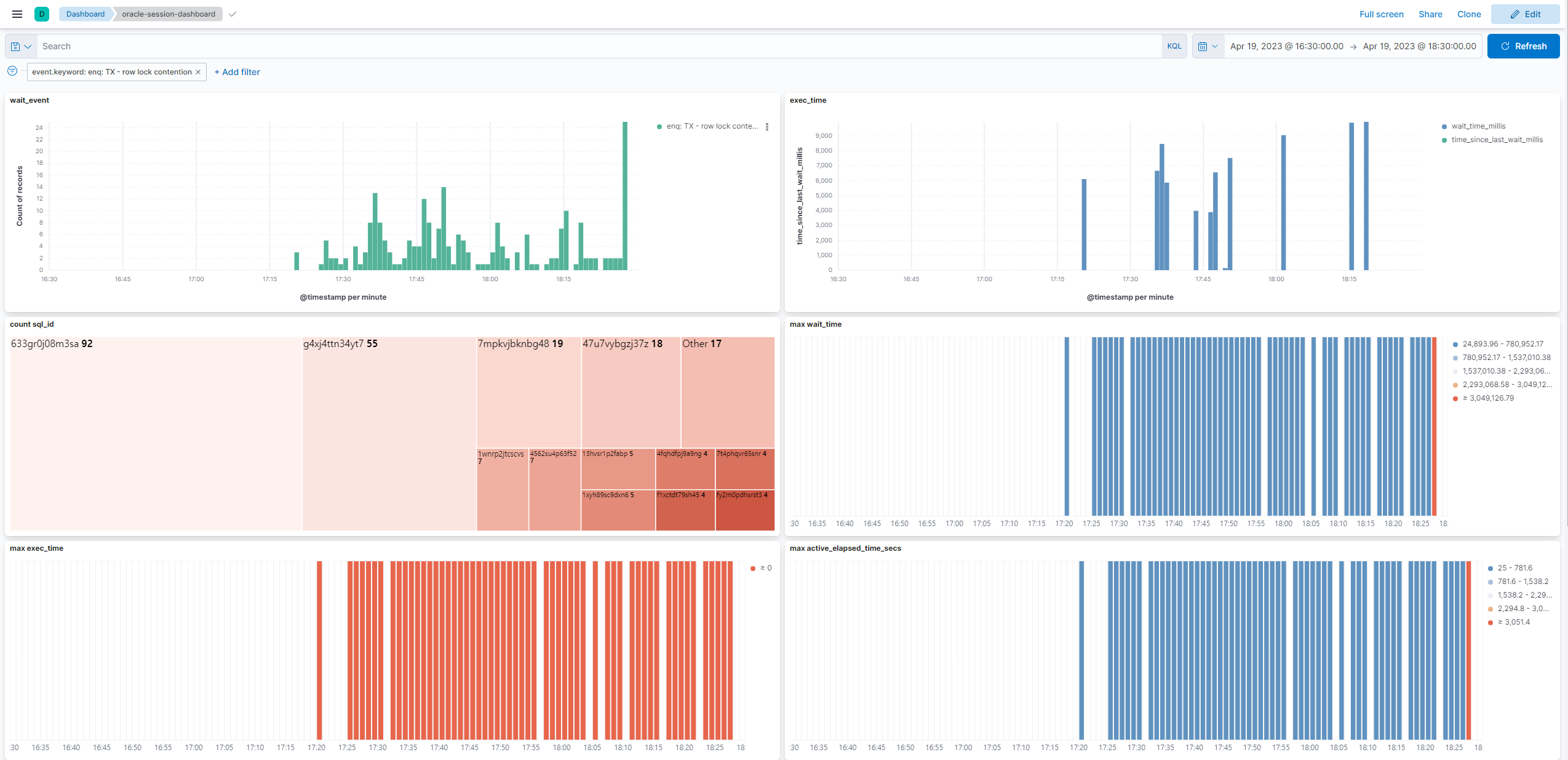
해당 Wait Event가 발생한 SQL을 확인해보니 데이터 집계 후 집계 데이터를 마스터 테이블(Master Table)에 업데이트하는 쿼리가 많았습니다.
분명 이 쿼리가 만들어질 당시에는 데이터가 많지 않아서 문제가 없었을 것입니다…
주목할 것은, 오라클에서 발생하는 Lock 경합의 대부분을 차지하는
enq: TM - contention이벤트3와enq: TX - row lock contention이벤트4가 Concurrency가 아닌 Application으로 분류돼 있다는 사실입니다. … 이런 유형의 프로그램 오류와 같이 분류한 것은 이들 문제가 DBA 이슈가 아니라 개발자 이슈임을 분명히 밝히고 있는 것입니다. Lock이 해제되지 않는 상황이 지속될 때 DBA가 할 수 있는 일은, Lock을 소유한 세션을 찾아 프로세스를 강제로 중지시키는 일뿐입니다. 근본적인 해법은 애플리케이션 로직에서 찾아야 합니다.5
결론
리소스를 효율적으로 사용하는 것은 어떤 기술을 사용하든 중요할 것입니다. 애초에 RDB가 적합하지 않을 수도 있습니다.6
기술 도입을 고려할 때 진단 도구도 중요한 고려 사항이라는 것을 느끼게 되었습니다. 기술 도입 후 진단 도구가 제공되지 않는다는 걸 알았다면, 시스템 장애에 대비하기 위해 직접 준비해야 할 수 있습니다.
참조
- Oracle Database 19
- 오라클 성능 고도화 - 원리와 해법 1, 조시형
각주
최종 수정: 2023-04-30