데모 서버는 markruler/htmltopdf 저장소를 사용해주세요.
개요
팀내에서 문서 생성 도구로 PDFmyURL과 OZ e-Form을 사용하고 있습니다. 보통 이런 외부 솔루션은 테스트 할 때 매우 불편합니다.
PDFmyURL은 PDF를 생성하는 2가지 인터페이스가 있습니다. 하나는 URL을 통해 페이지를 읽어서 PDF를 생성하는 인터페이스고, 하나는 raw HTML, CSS를 직접 전달해서 PDF를 생성하는 인터페이스입니다. URL 방식은 PDFmyURL 측 서버(서비스 외부)에서 페이지를 조회할 수 있어야 합니다. 그래서 private 환경에서는 테스트 할 수가 없습니다. 해당 기능들은 운영 환경에서 QA 테스트를 해야 하는 불상사가 생기는 겁니다. 더 큰 문제는 데이터를 Public 환경에 노출해야 하기 때문에 데이터에 따라 개인 정보 유출 문제가 될 수 있습니다.
OZ e-Form의 클라이언트 프로그램(OZ e-Form Designer)은 Windows만 지원합니다. 그리고 OZ 에이전트와 script를 적극적으로 관리할 인력이 없습니다. 해당 기술은 활용도가 떨어지기 때문에 관심이 적을 수 밖에 없기 때문입니다.
그러다가 누군가의 실수로 PDFmyURL 서버에 동시에 수많은 요청을 보내게 되었습니다. 그러자 PDFmyURL은 우리를 차단해버렸습니다. 문의를 남겨도 해외 서비스라 그런지 대응이 느렸고, PDFmyURL을 이용하는 서비스가 반나절동안 중단되었습니다. 언제 해결될지 기약이 없었습니다. 결국 다른 계정으로 라이센스를 추가 발급받아 해결했습니다.
내부에서 관리 가능한 HTML to PDF 변환 도구가 간절하다고 느낀 시기였습니다.
1차 시도: wkhtmltopdf
이런 프로그램을 제작해 본 경험자가 없어서 막연히 ChatGPT에게 물어봤습니다. 가장 먼저 답변해준 방법은 wkhtmltopdf였습니다.
# 해당 도구는 한글을 출력하기 위해 한글 폰트를 별도 설치해야 했습니다.
apt-get -y install fonts-nanum wkhtmltopdf
빠르게 시작하기 위해 Python의 pdfkit과 오픈 소스 PDF 변환 툴인 wkhtmltopdf를 사용해서 Flask 앱을 만들었습니다.
하지만 기존 출력물(크롬에서 window.print())과
달리 PDF 출력물을 보면 CSS가 틀어지는 부분이 너무 많았습니다.
리뷰하는 과정에서 확인해보니 문서를 읽지 않은 저의 잘못이었습니다.
해당 홈페이지 첫 문장부터 Qt WebKit rendering engine 이라고 설명합니다.
wk는 WebKit의 약자였고, Qt WebKit을 기반으로 변환하다보니 Chromium 기반으로 작성되어 있는 HTML이 그대로 보일 리 없었습니다.
Comparison of browser engines | Wikipedia
2차 시도: pyppeteer
기존에 Python으로 작성된 코드를 재사용하려고 Javascript 기반의 puppeteer 대신 python 기반의 pyppeteer을 사용했습니다.
# Ubuntu 22.04에서 google-chrome 명령어 설치
apt-get update \
&& apt-get install -y wget gnupg \
&& wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | gpg --dearmor -o /usr/share/keyrings/googlechrome-linux-keyring.gpg \
&& sh -c 'echo "deb [arch=amd64 signed-by=/usr/share/keyrings/googlechrome-linux-keyring.gpg] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list' \
&& apt-get update \
&& apt-get install -y google-chrome-stable fonts-ipafont-gothic fonts-wqy-zenhei fonts-thai-tlwg fonts-khmeros fonts-kacst fonts-freefont-ttf libxss1 \
--no-install-recommends \
&& rm -rf /var/lib/apt/lists/* \
&& groupadd -r pptruser && useradd -rm -g pptruser -G audio,video pptruser
google-chrome을 headless 모드로 실행해서 프린트하면 출력물이 브라우저 프린트(window.print())와 동일하게 나왔습니다.
(팀원 모두 Edge 아니면 Chrome을 사용함)
또한 private 환경에서도 출력할 수 있게 되었습니다.
window.print()로 출력
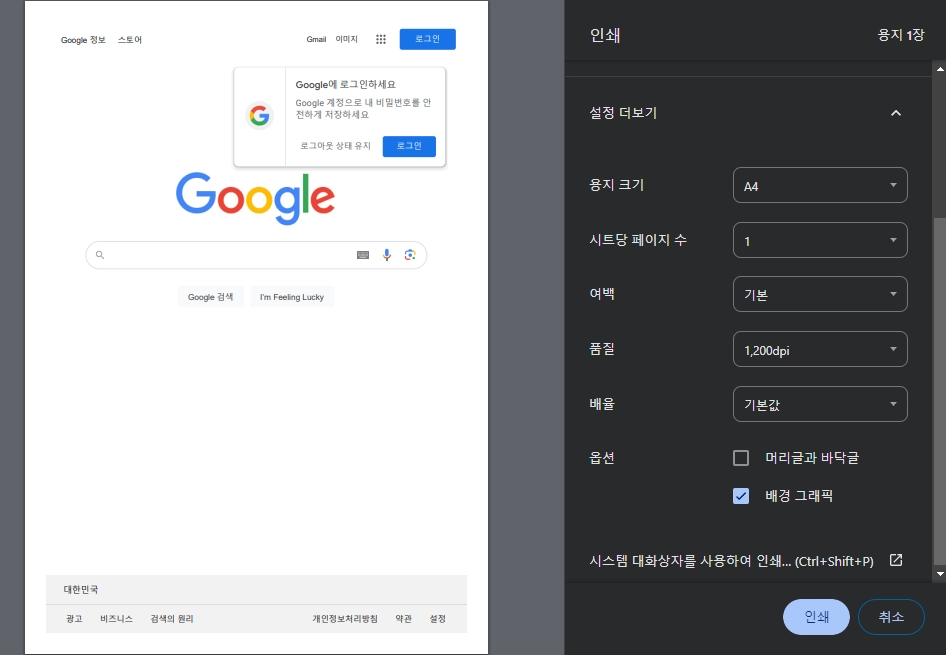
Pyppeteer로 출력
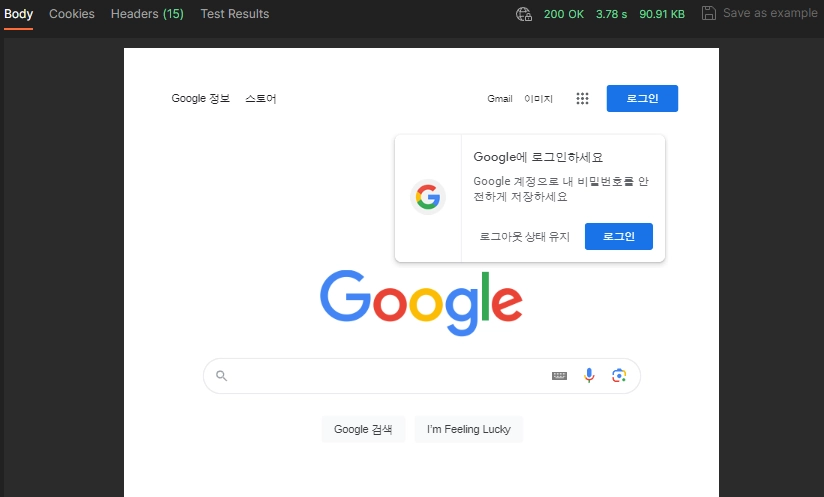
3차 시도: microsoft/playwright
URL이 아닌 Raw HTML, Raw CSS를 전달해서 PDF를 출력하는 기능도 지원되어야 했습니다. pyppeteer에선 HTML Content를 렌더링 할 때 Load 되는 것을 기다리지 않아 이미지 렌더링(img src, background url 등)이 되지 않았습니다.
setContent()시waitUntil옵션을 puppeteer만 지원하고 있습니다.
반면 Microsoft의 playwright는 해당 기능들을 모두 지원하면서, Javascript는 물론 Python도 지원했습니다. 결국 Content로 PDF를 출력하는 기능도 지원하기 위해 playwright로 변경했습니다. puppeteer와 인터페이스를 유사하게 만들었기 때문에 변경하는 데에 많은 리소스가 들지 않았습니다.
다음은 간단한 Raw Content를 PDF로 출력하는 토막 코드입니다.
# python3 -m pip install playwright
# python3 -m playwright install chromium # Download to $HOME/.cache/ms-playwright/
# python3 main.py
import logging
import asyncio
from playwright.async_api import async_playwright, Playwright, PlaywrightContextManager, Browser, BrowserContext
async def core_file():
playwright_context_manager: PlaywrightContextManager = async_playwright()
# https://playwright.dev/python/docs/api/class-playwright
playwright: Playwright = await playwright_context_manager.start()
# https://playwright.dev/python/docs/api/class-browsertype#browser-type-launch
browser: Browser = await playwright.chromium.launch(
headless=True,
timeout=10_000, # (ms)
args=[
# https://peter.sh/experiments/chromium-command-line-switches/
"--no-sandbox",
"--single-process",
"--disable-dev-shm-usage",
"--disable-gpu",
"--no-zygote",
],
# avoid "signal only works in main thread of the main interpreter"
handle_sigint=False,
handle_sigterm=False,
handle_sighup=False,
)
# https://playwright.dev/python/docs/api/class-browser#browser-new-context
logging.debug('new_context:new_page')
context: BrowserContext = await browser.new_context()
page = await context.new_page()
# https://playwright.dev/python/docs/api/class-page#page-goto
logging.debug('set_content')
await page.set_content(
html='<div><span>Test</span> Text</div>',
timeout=10_000,
# load로 해야 img.src가 로드됨.
wait_until='load' # domcontentloaded, load, networkidle
)
logging.info('add_style_tag')
await page.add_style_tag(
content='span{color:red;}'
)
# https://playwright.dev/python/docs/api/class-page#page-pdf
logging.debug('Generate PDF')
_pdf = await page.pdf(
format='A4',
landscape=False,
print_background=True,
display_header_footer=False,
margin={
'top': '10mm',
'bottom': '10mm',
'left': '10mm',
'right': '10mm',
}
)
print(_pdf)
await context.close() # don't forget to close the context, or it will create a core.{number} file.
await browser.close()
await playwright.stop()
# python3 main.py
if __name__ == '__main__':
asyncio.run(core_file())
구현 시 참고 사항
- CSS attribute 중
page-break-***를 사용하면 페이지를 원하는 부분에서 분리할 수 있습니다.page-break-after: always;해당 Element 이후에 내용이 있더라도 페이지를 분리합니다.page-break-after: avoid;해당 Element 이후에 페이지는 분리하지 않습니다. 이후 내용이 페이지를 넘친다면 페이지가 분리되긴 합니다.
- PDF 생성 후 응답되기까지 2초 정도 소요됩니다.
- PDFmyURL, OZ report와 비슷합니다.
- 1주일 기준
- P50: 2.01s
- P95: 2.83s
- Server to Server로 요청 시 Spring Boot에서 FeignClient로
x-www-form-urlencoded
데이터를 보내려면
MultiValueMap<String, String>을 사용해야 합니다.
참조
Playwright
WebKit
Chromium
- Chrome’s Headless mode gets an upgrade: introducing –headless=new | Chromium | Chrome for Developers
최종 수정: 2024-12-10