절판된 책이나 집에서 보관하던 두꺼운 책을 스캔해서 소장하고 싶은 경우가 있습니다. 그래서 저는 비파괴 스캐너를 구입해서 거의 10년 동안 책을 스캔해서 보관하고 있습니다.1 하지만 펼칠 때마다 목차2가 없으면 발췌독하기 불편한데요. 오픈 소스 OCR 도구인 Tesseract를 이용해 PDF 목차를 만들어보겠습니다.
사적이용을 위한 저작권법
먼저 저작권에 대해 확인해야 할 부분이 있습니다. 과연 책을 스캔해서 PDF로 만드는 것이 합법일까요? 인터넷에 검색해보면 도서관에서 빌린 책을 스캔하는 건 불법이라고 하는 경우가 많은 것 같습니다. 저작권법 제30조를 보면 다음과 같이 명시되어 있습니다.
제30조(사적이용을 위한 복제) 공표된 저작물을 영리를 목적으로 하지 아니하고 개인적으로 이용하거나 가정 및 이에 준하는 한정된 범위 안에서 이용하는 경우에는 그 이용자는 이를 복제할 수 있다. 다만, 공중의 사용에 제공하기 위하여 설치된 복사기기, 스캐너, 사진기 등 문화체육관광부령으로 정하는 복제기기에 의한 복제는 그러하지 아니하다. <개정 2020. 2. 4.>
이 조항에 대해서도 인터넷 커뮤니티에서는 “개인이 구매한 서적만 가능한 것이다"라고 해석하는 경우가 많은 것 같습니다. 유명한 테크 유튜브 채널인 테크몽에서도 한국저작권위원회에 직접 문의한 결과 문제가 없다고 합니다. 한국저작권보호원의 영상 댓글에서도 이 경우에는 문제없다고 하죠.
공표된 저작물을 영리를 목적으로 하지 아니하고 개인적으로 이용하거나 가정 및 이에 준하는 한정된 범위 안에서 이용하는 경우에는 그 이용자는 이를 복제할 수 있습니다(저작권법 제30조). 이를 ‘사적이용을 위한 복제’ 통칭 사적 복제라고 하며, 구입한 CD를 핸드폰에 넣어 듣기 위하여 mp3파일로 변환하는 행위, 다운로드받은 영화를 TV에서 보기 위하여 usb에 옮기는 행위, 구입한 책에 필기를 하기 위하여 복사하는 행위 등이 해당할 수 있습니다. 관련하여, 도서관에서 빌린 책을 직접 스캔 또는 사진으로 찍어 귀하 소유의 핸드폰으로 읽는 것은 사적복제로서 저작권 침해가 되지 않습니다. 그러나 이를 업체 등에 맡겨 스캔하거나, 스캔한 결과물을 한정된 범위 외의 다른 사람에게 보여주게 되면 사적 복제의 범위를 넘어 복제권 침해가 성립할 수 있음을 주의하여 주시기 바랍니다.
즉, 자신이 소유한 또는 도서관에서 빌린 서적을 개인적으로 이용하기 위해 자신이 소유한 복제기기로 직접 스캔한 경우 적법한 행위입니다. 이쯤이면 저작권법 제30조가 다르게 해석3될 여지는 없을 것 같습니다.
PDF 읽기
PDF는 Adobe 사에서 개발한 파일 형식으로, 다양한 운영체제에서 동일한 형식으로 문서를 표현할 수 있습니다. 여기서는 Python 모듈인 PyMuPDF를 사용해서 PDF를 읽어보겠습니다.
pdf_file: pymupdf.Document = pymupdf.open(self.filename)
OCR (Optical Character Recognition)
OCR은 광학 문자 인식(Optical Character Recognition)의 약자로, 이미지나 문서를 스캔해서 텍스트로 변환하는 기술입니다. 스캐너로 스캔한 책은 이미지로 저장이 되는데요. 이 이미지를 텍스트로 변환해서 PDF outline을 만들어보겠습니다.
먼저 오픈 소스 도구인 Tesseract OCR를 설치해야 합니다.
이후 Tesseract OCR 설치 경로의 tessdata 디렉토리에 훈련 모델(kor.tessdata)을 다운로드합니다.
page = pdf_file[0]
images = page.get_images()
for img in images:
base_image = pdf_file.extract_image(img[0])
image = Image.open(io.BytesIO(base_image["image"]))
txt = pytesseract.image_to_string(image, lang="eng+kor") # 영어와 한국어를 인식
PyQt6
PyQt6는 Qt 프레임워크의 Python 바인딩으로, Qt는 크로스 플랫폼 GUI 프레임워크입니다. 위 조각 코드들을 조합해서 PyQt6로 PDF outline을 만드는 GUI 프로그램을 만들 수 있습니다.
app = QApplication(sys.argv)
window = App()
window.show()
sys.exit(app.exec())
QThread를 사용해서 OCR 작업을 별도의 스레드에서 처리해야 Blocking 되는 것을 피할 수 있습니다.
# https://wikidocs.net/71014
class Worker(QThread):
def __init__(self, parent=None):
super().__init__(parent)
self.filename = None
def run(self):
# ...
다음 화면은 개인적으로 사용하기 위해 만든 프로그램입니다. 목차 부분을 OCR로 추출해서 편집할 수 있습니다. 편집된 목차를 두고 Write outline 버튼을 누르면 목차가 포함된 새 파일이 저장됩니다. 페이지는 직접 PDF에서 입력해야 하지만 귀찮은 일을 많이 줄일 수 있습니다.
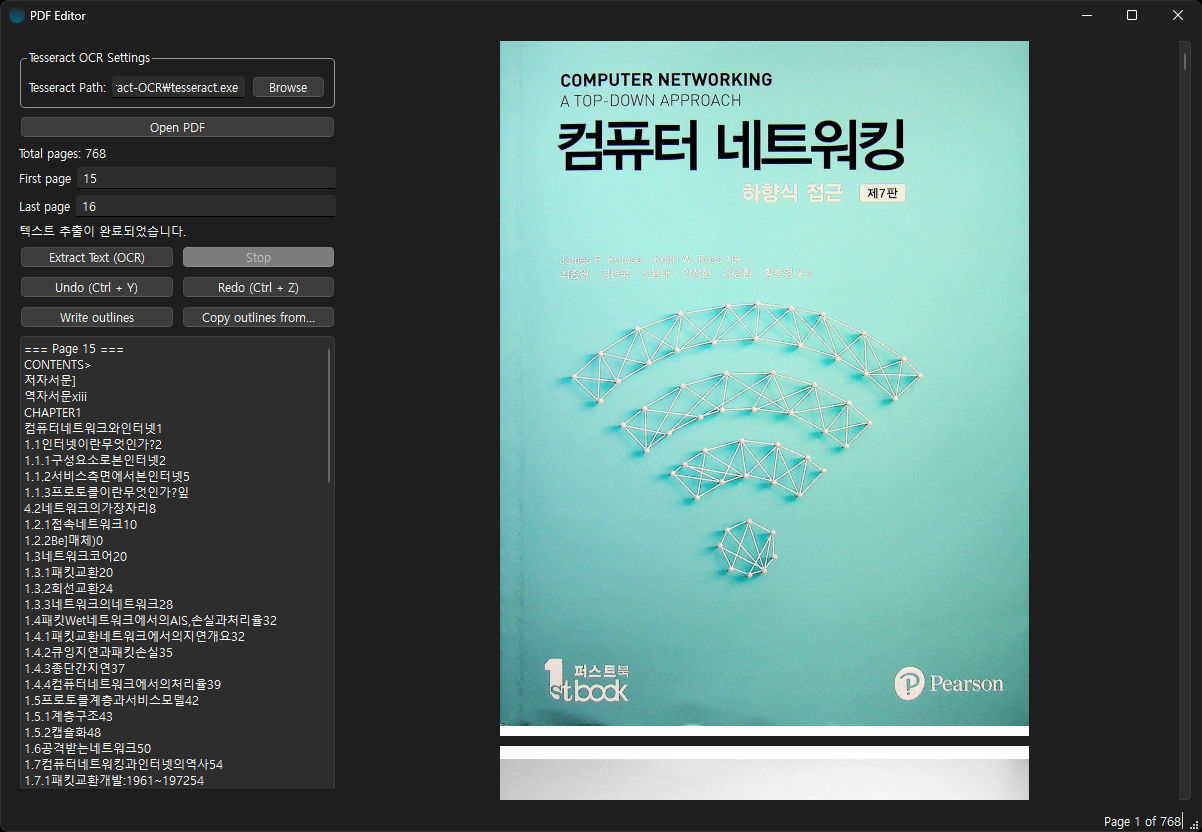
기본적으로 제공된 훈련 데이터의 정확도가 높은 편은 아니지만, 일일이 타이핑하는 것보다는 훨씬 편리하고 빠릅니다.
최종 수정: 2025-01-27