엘라스틱서치(Elasticsearch)는 문서 기반 검색 엔진으로 빠른 키워드 검색 속도를 제공합니다.
엘라스틱서치가 빠른 이유는 문서의 단어(term)들을 역색인(inverted index)하기 때문입니다.
책에서 특정 단어를 찾는 걸 상상해 보죠.
관계형 데이터베이스(RDB, Relational Database)는 LIKE 검색을 통해 검색 키워드가 포함된 모든 페이지를 찾아야 합니다.
엘라스틱서치는 책 뒷부분에 있는 색인(index)을 보고 필요한 페이지만 찾으면 됩니다.
이 글에서는 e커머스 서비스에서 검색 성능을 개선하기 위해 도입한 엘라스틱서치와 인덱싱 전략에 대해 소개합니다.
엘라스틱서치 도입 배경
매일 새벽에 장애가 발생하기 시작했습니다. 유저 트래픽이 주로 새벽에 몰리는데, 이때 DB 레이턴시가 높아져서 모든 서버에 장애가 발생했습니다. 왜 DB 레이턴시가 높았을까요? 현재 서비스에서 트래픽이 가장 많이 발생하는 페이지가 메인, 상품 검색, 상품 상세 페이지입니다. 이 중 검색 페이지에서 쿼리 대기 시간이 길어지고 있었습니다. 원인은 크게 다음과 같습니다.
LIKE %keyword%검색 — 최악의 경우 DB는 모든 레코드를 찾아야 합니다.- 검색 페이지가 증가할수록 검색 속도는 더 느려졌습니다.
- 상품 수의 급증 — 상품 수가 약 50만 개에서 270만 개로 증가했습니다.
- 판매 중인 상품만 보면 약 6만 개에서 76만 개로 증가했습니다.
- 개선 전에는 판매된 상품도 검색 결과에 포함되어 있었습니다.
당장 개선이 필요했습니다. RDB에도 역인덱싱 타입이 있었지만, 참조할 만한 문서가 많지 않았습니다. 더 중요한 건 RDB에 부하가 발생하고 있었기 때문에 RDB에서 작업할 수 없던 상황이었습니다. 당시 검색 키워드를 저장하고 집계만 하던 기능에 사용되던 Elastic Cloud가 있었고, MSP(Managed Service Provider)를 통해 계약되어 있던 상태라 기술지원을 받을 수 있었습니다. 그래서 빠른 도입과 개선을 위해 관리형 서비스(Managed Service)를 쓰는 게 더 낫다고 판단했습니다.
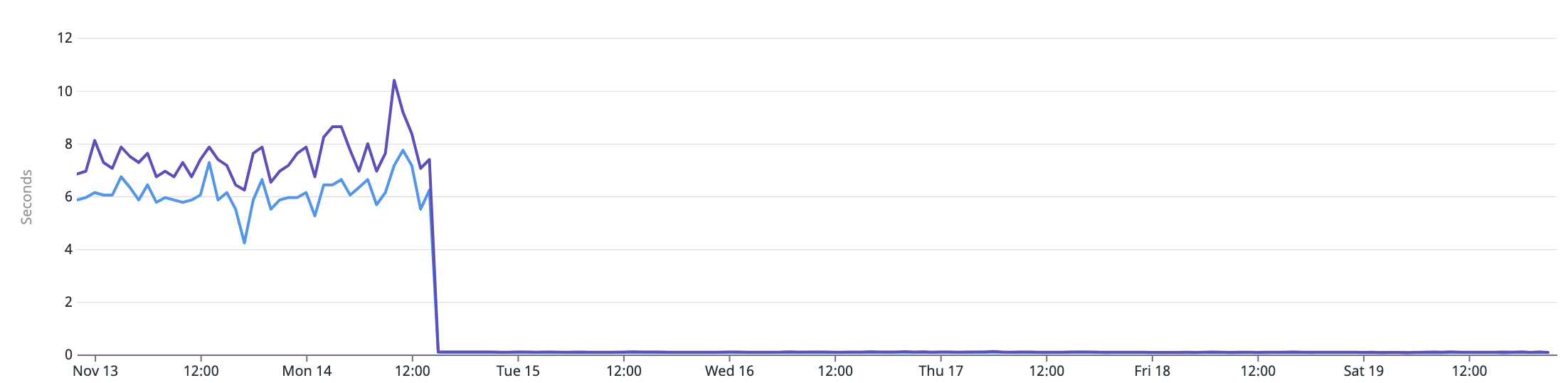
엘라스틱서치를 검색 기능에 도입 후 서버 응답 속도 (Datadog APM)
- 개선 전 평균 응답 시간: 약 6,000~7,000ms (7일 집계)
- 개선 후 평균 응답 시간: 약 80~100ms (7일 집계)
RDB 데이터를 인덱싱하는 전략
1. 가장 쉬운 방법 Batch
처음엔 Elastic 공식 문서를 참조해서 로그스태시(Logstash)1로 시작했지만 원하는 로그와 커스텀 동작을 추가하기 힘들었습니다. 그래서 성능 개선 후 바로 파이썬(Python) 스크립트로 전환했습니다. 대략적인 ETL 과정은 다음과 같습니다.
- Extract: Oracle DBMS에서 마지막으로 조회한 최근 수정된 날짜(
updated_at) 기준 이후로 데이터 조회 - Transform: 엘라스틱서치 인덱스의 스키마(Schema)에 맞게 데이터 수정
- Load: 엘라스틱서치에 데이터 인덱싱
2. UPDATE 데이터
시간이 지날수록 RDB 데이터와 Elasticsearch 데이터에 차이가 발생하기 시작했습니다. (평균 약 300개/1d) 이러한 이유로 엘라스틱서치에서 조회 후 RDB에서 한번 더 조회하는 방식을 사용했습니다.
Python의 deepdiff 모듈을 사용해서 RDB와 엘라스틱서치 데이터 전체를 비교해봤습니다.
특정 패턴을 분석해보니 내가 파악하지 못한 레거시 시스템이나 스케줄러에서 updated_at을 업데이트 하지 않고 데이터를 수정한다는 것을 알게 되었습니다.
추가로 트랜잭션 문제로 인해 데이터에 차이가 발생하는 경우도 있었습니다.2
간략히 설명하면 데이터 UPDATE를 위한 트랜잭션 시작 후 COMMIT 전에 배치 작업이 SELECT를 실행하면 업데이트 이벤트가 누락될 수 있습니다.
updated_at 기준이 아닌 전체 인덱싱도 고려해야 한다는 것을 느끼고 2가지 배치를 동시에 실행하기 시작했습니다.
- 실시간 배치 —
updated_at을 기준으로 5초 Fixed Delay - 전체 배치 — 최근 데이터까지 인덱싱하면 다시 처음부터 반복 (약 3시간 소요)
3. HARD DELETE 데이터
수정 후 데이터 차이가 많이 줄었습니다. (평균 약 2개/1d) 하지만 남은 건 어디서 발생하는지 한참 찾아야 했습니다. 운영상 상품을 HARD DELETE3 해야 하는 상황이 있었고, 이 정보가 팀원 간에 공유되지 않았습니다. 지금까지 설명한 배치 방식은 Hard Delete에 대응하지 못합니다.
다른 대안이 있을까 찾아봤더니 CDC(Change Data Capture)와 같은 스트림(Stream) 방식을 사용할 수 있습니다. 하지만 Oracle CDC4, Apache Kafka Streams 혹은 Apache Flink 등의 시스템을 추가로 학습하고 도입해서 관리해야 한다는 점 때문에 선택하지 않았습니다.
그럼 또 다른 대안이 있을까요? 상품 인덱스에 alias를 지정하고, 1일 1번 새로운 인덱스를 생성해서 변경하기로 했습니다.
예를 들어 product-20220102 인덱스를 생성하고,
전체 문서 인덱싱을 완료할 경우 product alias를 product-20220101에서 product-20220102로 변경합니다.
그럼 Hard Delete가 발생해도 최대 1일 동안만 차이가 발생합니다.
더 개선할 수 있는 부분
검색 기능 구현에 Spring Data Elasticsearch 모듈을 사용했습니다.
인덱스 스키마를 Python과 Java 언어로 된 2개의 프로젝트에서 관리하는 것입니다.
엘라스틱서치 인덱스는 @Entity로 정의했는데 이를 별도 모듈로 재사용하면 Spring Batch를 사용할 수 있습니다.
현재 전체 데이터를 인덱싱하는데 평균 3시간이 걸립니다.
파이썬은 GIL(Global Interpreter Lock) 때문에 multiprocessing 모듈을 사용해야 병렬 처리가 가능하지만,
Spring Batch로 전환하면 배치 작업을 병럴 처리해서 처리 속도를 향상시킬 수 있습니다.
하지만 Elastic Cloud를 사용한다면 비용(Credit)도 고려해야 합니다. 데이터 인덱싱을 더 많이, 더 자주 해보니 데이터 노드의 CPU 사용량이 높아지는 것을 확인했습니다.
검색 기능의 서버 응답 속도는 평균 85.2ms/1w 입니다5. 데이터에 차이가 발생하는 문제 때문에 엘라스틱서치에서 조회 후 RDB에서 한번 더 조회하는 방식을 사용했는데, 배치 처리 속도를 개선하면 RDB를 조회하는 부분을 제거할 수 있습니다. 게다가 현재 서비스의 주요 이용자들은 아프리카, 중남미, 중앙아시아 지역인데 여기서 검색 시 평균 응답 속도가 2.26s/1w 입니다6. RDB를 조회할 필요가 없어지면 마케팅 집중 국가와 가장 가까운 지역에 검색 서버를 두어서 응답 속도를 개선할 수 있을 것입니다.
이 고민을 저만 했던 게 아니었습니다
- Tune for indexing speed | Elastic
- 엘라스틱서치를 이용한 상품 검색 엔진 개발 일지 | NHN FORWARD 22
- 샵바이 주문 검색 성능 개선기 | NHN FORWARD 22
- What is change data capture (CDC)? | Red Hat
-
Hard Delete란 데이터를 삭제할 때 실제 데이터를 삭제하는 것을 말합니다. SQL에서는
DELETE. 이와 반대로 Soft Delete는 삭제 플래그(ex:is_deleted)만 수정하고 데이터를 삭제하지 않습니다. ↩︎ -
Oracle Streams는 Oracle DBMS에 무료로 제공된 Oracle의 기본 CDC 도구였지만 12c 버전부터 Deprecated 되었습니다. 또 Debezium과 같은 오픈 소스 CDC 도구들은 Oracle LogMiner에서 redo log를 읽는 방식이었지만 19c부터 LogMiner는 Deprecated 되었습니다. Oracle GoldenGate라는 유료 CDC 도구를 만들고 이를 사용하도록 유도하기 위해… ↩︎
-
Avg: 85.2ms, P50:87.7ms, P75:106ms, P95:140ms (Datadog APM 최근 1주일 집계) ↩︎
-
Datadog RUM 측정 기준 ↩︎
최종 수정: 2024-09-08