개요
현재 팀에서 빌드-배포 도구로 Bamboo를 사용하고 있다. 놀랍게도 개발자가 커밋한 소스 코드를 운영 환경에 반영하기까지 14단계의 수동 작업이 필요했다. 그래서 개발팀 모두가 배포 작업에 많은 부담을 갖고 있었다. 한번 빌드하고 배포하는데 최소 30분에서 길면 1시간까지 걸리는 이 불필요한 시간을 줄이고 싶었다.
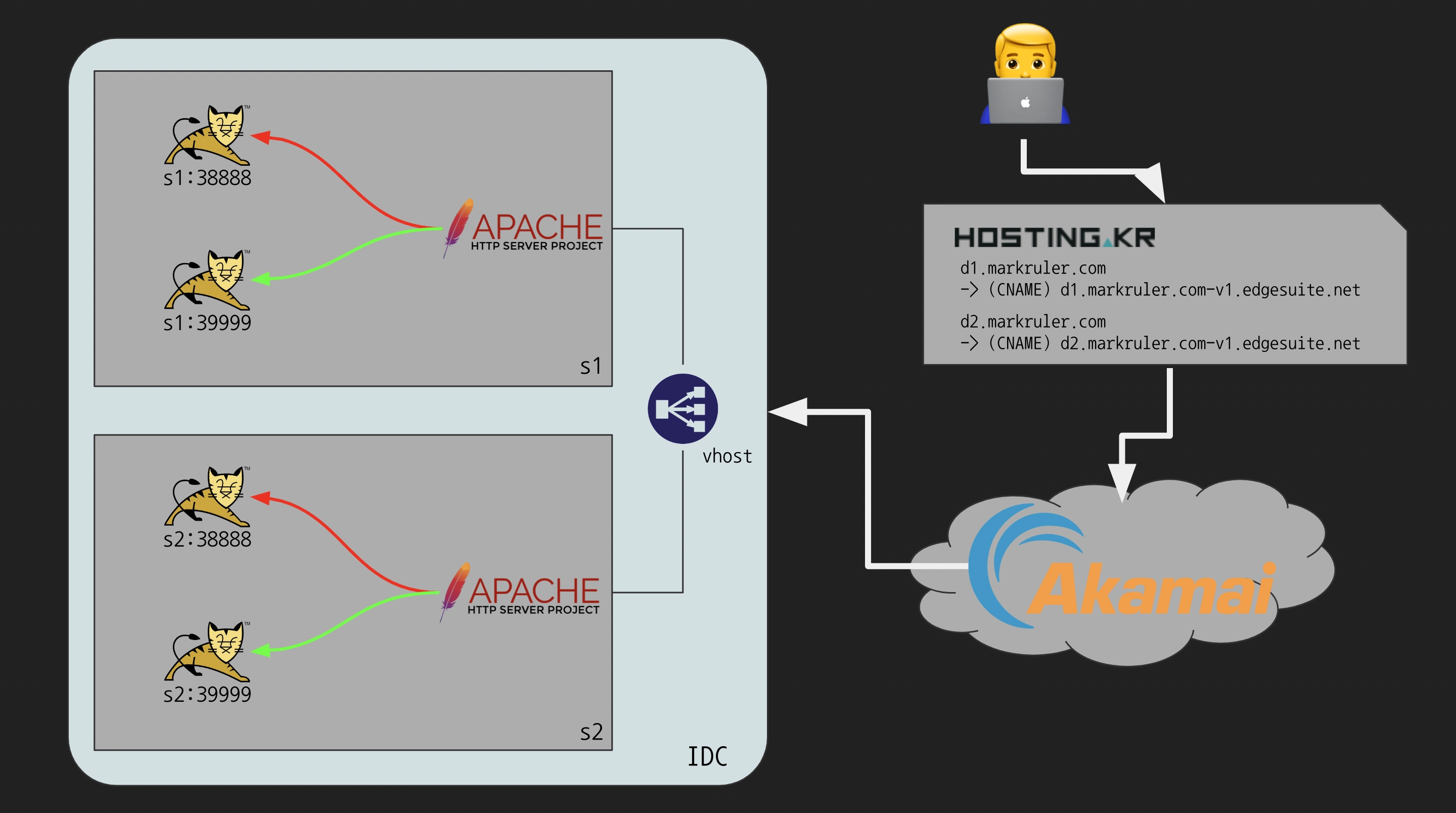
화살표 방향은 단순히 요청의 흐름을 나타낸다.
단일 서버의 처리량(Capacity)을 초과한 대량 요청 트래픽은 속도 저하나 서비스 지연 또는 장애를 유발한다.
이 상황을 대비해 부하(Load)를 여러 서버로 분산(Balancing)하는 것을 서버 로드 밸런싱(SLB: Server Load Balancing)이라고 한다.1
기존 운영 환경에서는 Alteon Application Switch를 Layer 4 로드 밸런서로 사용하고 있었다.
하지만 80번 포트에 대한 Layer 4 헬스체크만 하고 있었기 때문에 애플리케이션 배포 시 연결을 비활성화해야 했다.
배포 작업의 대부분이 이 작업에 의존했다.
웹 애플리케이션이 실행 중인 서버에 Apache HTTP 서버(httpd)도 있었기 때문에 가장 빠르고 효과적인 해결책으로 Layer 7 Load Balancing 기능을 생각했다.
정리하자면 기존 프로세스와 개선 프로세스는 다음과 같다.
기존 프로세스
- 코드 리뷰를 마치고 소스 코드가 배포 브랜치에 병합되면 버튼을 눌러 빌드한다.
- 대부분의 이슈들은 2개의 애플리케이션(
:38888,:39999)에 함께 반영된다.
- 대부분의 이슈들은 2개의 애플리케이션(
telnet을 사용해서 Alteon Switch에 접속한다.- 배포하기 전에 서비스 도메인(
d1.markruler.com,d2.markruler.com)에 접속할 수 있는지 확인한다. - 가상 호스트(vhost)에 묶여 있는
s1서버를 비활성화한다.
>> Server Load Balancing Information# /info/slb/virt 1
1: IP4 <vhost_IP_Address>, 00:00:00:00:00:00
virtual ports:
http: rport http, group 1, backup none, rtspslb none
real servers:
1: <s1_IP_Address>, backup none, 0 ms, group ena, up
2: <s2_IP_Address>, backup none, 0 ms, group ena, up
https: rport https, group 1, backup none, rtspslb none
real servers:
1: <s1_IP_Address>, backup none, 0 ms, group ena, up
2: <s2_IP_Address>, backup none, 0 ms, group ena, up
>> Main# /cfg/slb/real 1/dis
Current status: enabled
New status: disabled
>> Main# apply
- 다시 3번과 동일하게 서비스 도메인에 접속할 수 있는지 확인한다.
- Bamboo를 사용해서 새로운 버전의 애플리케이션 2개(
s1:38888,s1:39999)를 배포한다. - 배포 스크립트에서 별도로 헬스체크를 하지 않기 때문에 수동으로 접속할 수 있는지 확인(“새로 고침”)한다.
- 정상적으로 접속되면 Alteon Switch에서
s1서버를 활성화한다.
>> Main# /cfg/slb/real 1/ena
Current status: disabled
New status: enabled
>> Main# apply
- 그 후
s2서버를 비활성화한다. (8번과 동시에 적용하면 Akamai CDN 서비스에서ERR_ZERO_SIZE_OBJECT에러가 발생할 수 있다) - 다시 3번과 동일하게 서비스 도메인에 접속할 수 있는지 확인한다.
- Bamboo에서 새로운 버전의 애플리케이션 2개(
s2:38888,s2:39999)를 배포한다. - 다시 7번과 동일한 이유로 서비스 도메인에 접속할 수 있는지 확인한다.
- 모두 접속되면 Alteon Switch에서
s2서버를 활성화한다. - 마지막으로 반영 사항을 갈무리해서 업무 메신저에 공유한다.
개선 프로세스 (Continuous Delivery)
웹 서버가 동일 머신에 있는 웹 애플리케이션만 바라보는 것이 아니라 다른 머신에 있는 서버도 바라보도록 설정했다.
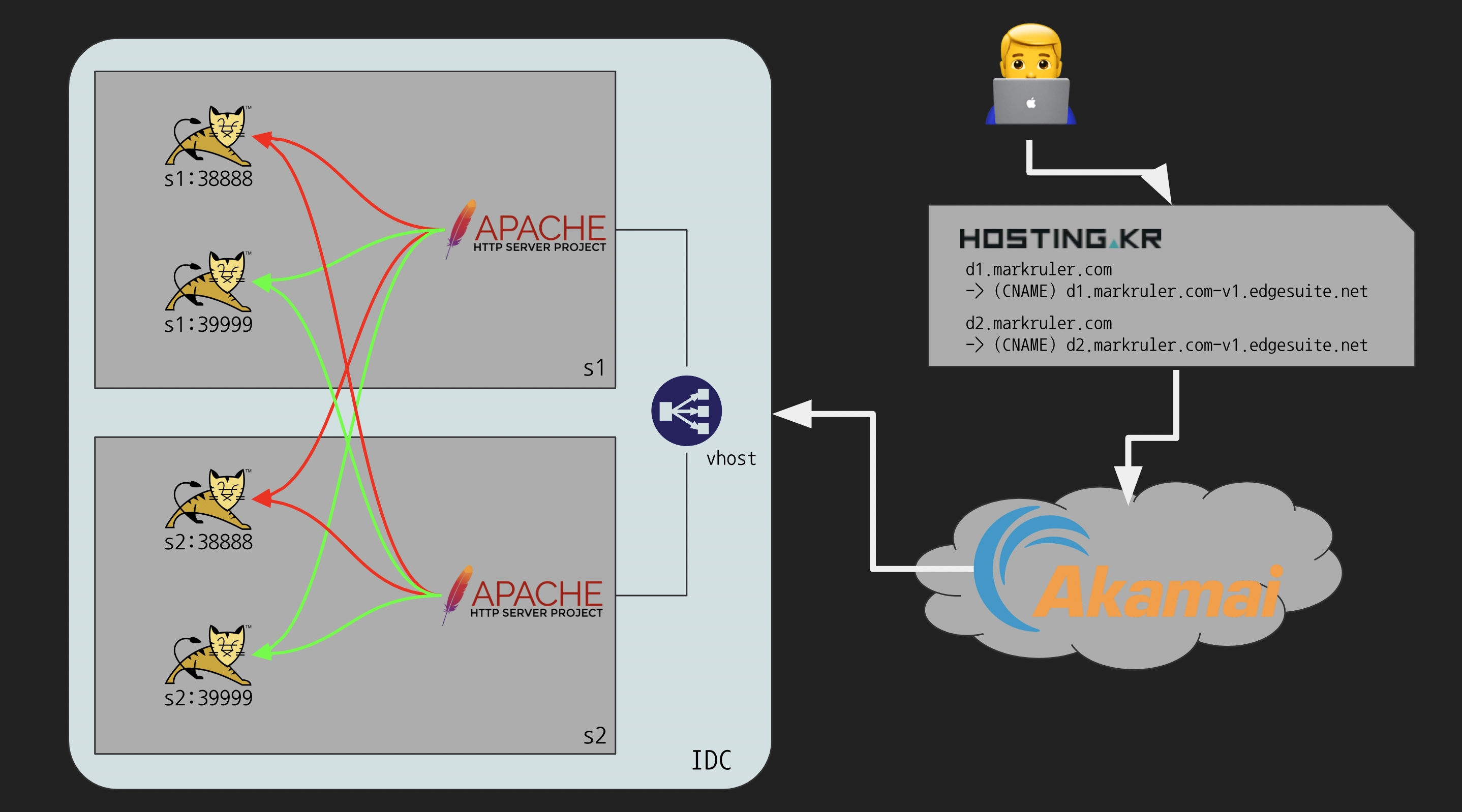
총 14단계에서 1단계까지 줄였다. 먼저 코드 리뷰를 마치고 소스 코드가 통합 브랜치(trunk)에 병합되면 자동으로 빌드된다.
- 운영 환경에 반영하기 위해 배포 버튼을 누른다.
-
쉘 스크립트를 활용해 자동으로 새로운 버전의 애플리케이션을 배포하고 헬스체크한다.
#!/usr/bin/env bash while ! curl --silent --output /dev/null --head --fail --max-time 3 --location ${1}; do echo "Healthchecking...${1}" sleep 2 done
-
마지막으로 반영 사항을 갈무리해서 업무 메신저에 공유한다.- 업무 메신저가 Slack에서 NAVER Works로 변경되고 연동을 못하고 있었는데 Jenkins 플러그인을 직접 만들어서 알림 메시지가 가도록 만들었다.
도입 과정에서 발생한 문제들
Active Health Check가 필요하다
Active Health Check란 주기적으로 서버에 연결을 시도하거나 HTTP 요청을 보내서 서버 상태를 확인한다. 반면 Passive Health Check는 오류가 있는지 활성 트래픽(active traffic)만 검사한다.
s1 과 s2 서버에는 CentOS 7이 설치되어있다.
해당 OS에서는 httpd를 2.4.6 버전까지만 업데이트 할 수 있다.
> yum info httpd
...
Available Packages
Name : httpd
Arch : x86_64
Version : 2.4.6
...
Layer 7 헬스체크를 위한 mod_proxy_hcheck 모듈은
2.4.21 버전부터 사용할 수 있기 때문에 OS 변경이 불가피했다.
하지만 클라우드 컴퓨트 서비스를 사용하는 것이 아닌
IDC 물리 서버를 사용하고 있었기 때문에 OS 교체는 상당히 큰 부담이었다.
그래서 컨테이너를 도입하기로 결정했다.
설정 파일(httpd.conf)은 기존 설정을 최대한 그대로 사용하기로 했다.
volumes 경로는 어느 환경에서든 동일하도록 가급적 절대 경로를 사용했다.
> cd ${HOME}/httpd
> ls
docker-compose.yaml httpd.conf
# docker-compose.yaml
version: "3.8"
services:
slb:
image: httpd:2.4.54-alpine
container_name: slb
hostname: markruler.com
ports:
- 80:80
- 443:443
volumes:
# httpd
- '/home/markruler/httpd/httpd.conf:/usr/local/apache2/conf/httpd.conf'
# logs
- '/etc/httpd/logs/d1.markruler:/usr/local/apache2/logs/d1.markruler'
# SSL
- '/etc/ssl/certs/d1.crt:/etc/ssl/certs/d1/cert.pem'
- '/etc/ssl/certs/d1.key:/etc/ssl/certs/d1/privkey.pem'
- '/etc/ssl/certs/d1.chain.crt:/etc/ssl/certs/d1/chain.pem'
- '/etc/ssl/certs/CA_AAA_CERTIFICATE_SERVICES.crt:/etc/ssl/certs/d1/ca.pem'
# SSL Key Password
- '/etc/ssl/certs/key_password.sh:/etc/ssl/certs/d1/key_password.sh'
networks:
default:
driver_opts:
com.docker.network.enable_ipv6: "false"
ipam:
driver: default
config:
- subnet: 172.18.0.0/16 # 255.255.0.0
gateway: 172.18.0.1
httpd -t 명령어로 서버 실행 전 설정 파일을 검증할 수 있다.
sudo docker compose run --rm slb httpd -t
up 명령어로 서버를 실행한다.
# sudo docker compose up --detach
sudo docker compose -f ${HOME}/httpd/docker-compose.yaml up -d
docker inspect 명령어로 실제 실행된 컨테이너의 정보를 확인할 수 있다.
sudo docker inspect slb
iptables 서비스를 다시 시작해야 할 때
iptables 서비스를 다시 시작하면 /etc/sysconfig/iptables 파일에
있는 규칙들만 적용되기 때문에 Docker에서 설정하는 iptables 규칙이 사라진다.
> systemctl restart iptables
실제로 Docker 도입 사실을 IDC 매니저와 공유하지 않았다가 문제가 발생했다. IDC 매니저가 우리 회사 측 요청으로 iptables 규칙을 변경하고 재시작했는데 해당 서버의 Docker 네트워크 규칙들이 사라져서 컨테이너가 실행되지 못하고 있었다. 현재는 iptables를 재실행할 때 Docker도 같이 재실행한다.
> systemctl restart docker
> iptables -nvL
추가로 컨테이너에서 각 서비스로 트래픽을 보내기 위해 iptables 규칙을 추가한다.
Docker 데몬은 기본적으로 docker0 라는 브릿지 네트워크 인터페이스를 사용하는데 IP address range를
172.17.0.1/16 으로 설정한다.
> ip -br -c a
lo UNKNOWN 127.0.0.1/8 ::1/128
docker0 DOWN 172.17.0.1/16 # HERE!
iptables 규칙을 추가하기 위해 해당 네트워크를 고정시켰다. bip는 Docker 데몬이 사용할 bridge network IP address range를 지정하는 옵션이다.
# 기본 설정
cat <<EOF | sudo tee /etc/docker/daemon.json
{
"bip": "172.17.0.1/16"
}
EOF
Docker 데몬을 재시작하면 docker0 네트워크 인터페이스가 변경되어 있을 것이다.
이제 컨테이너에서 웹 애플리케이션으로 패킷을 전달할 수 있도록 iptables 규칙을 추가한다.
> vi /etc/sysconfig/iptables
-A INPUT -m state --state NEW -s 172.16.0.0/12 -m tcp -p tcp --dport 38888 -j ACCEPT
-A INPUT -m state --state NEW -s 172.16.0.0/12 -m tcp -p tcp --dport 39999 -j ACCEPT
172.16.0.0/12 로 설정한 이유는 docker-compose로 컨테이너를 실행할 경우
이미 있는 인터페이스가 아닌 추가 인터페이스를 생성하기 때문이다.
만약 docker0 와 동일한 172.17.0.1/16 으로 생성하려고 시도하면 아래와 같은 에러가 발생한다.
failed to create network httpd_default: Error response from daemon: Pool overlaps with other one on this address space
Docker에서 추가 인터페이스를 생성할 때 172.17-31.x.x/16, 192.168.x.x/20 범위에서 추가하게 된다.
// https://github.com/moby/moby/blob/df650a1aeb190a319287c4d26bd3593b5343fb72/libnetwork/ipamutils/utils.go
var (
// PredefinedLocalScopeDefaultNetworks contains a list of 31 IPv4 private networks with host size 16 and 12
// (172.17-31.x.x/16, 192.168.x.x/20) which do not overlap with the networks in `PredefinedGlobalScopeDefaultNetworks`
PredefinedLocalScopeDefaultNetworks []*net.IPNet
// PredefinedGlobalScopeDefaultNetworks contains a list of 64K IPv4 private networks with host size 8
// (10.x.x.x/24) which do not overlap with the networks in `PredefinedLocalScopeDefaultNetworks`
PredefinedGlobalScopeDefaultNetworks []*net.IPNet
mutex sync.Mutex
localScopeDefaultNetworks = []*NetworkToSplit{{"172.17.0.0/16", 16},
{"172.18.0.0/16", 16},
{"172.19.0.0/16", 16},
{"172.20.0.0/14", 16},
{"172.24.0.0/14", 16},
{"172.28.0.0/14", 16},
{"192.168.0.0/16", 20}}
globalScopeDefaultNetworks = []*NetworkToSplit{{"10.0.0.0/8", 24}}
)
func init() {
var err error
if PredefinedGlobalScopeDefaultNetworks, err = splitNetworks(globalScopeDefaultNetworks); err != nil {
panic("failed to initialize the global scope default address pool: " + err.Error())
}
if PredefinedLocalScopeDefaultNetworks, err = splitNetworks(localScopeDefaultNetworks); err != nil {
panic("failed to initialize the local scope default address pool: " + err.Error())
}
}
만약 범위를 변경하고 싶다면 Mirantis 문서처럼 default-address-pools 옵션을 직접 추가할 수 있다.
{
"default-address-pools": [
{"base":"172.17.0.0/16","size":16}, <-- docker0
{"base":"172.18.0.0/16","size":16},
{"base":"172.19.0.0/16","size":16},
{"base":"172.20.0.0/16","size":16},
{"base":"172.21.0.0/16","size":16},
{"base":"172.22.0.0/16","size":16},
{"base":"172.23.0.0/16","size":16},
{"base":"172.24.0.0/16","size":16},
{"base":"172.25.0.0/16","size":16},
{"base":"172.26.0.0/16","size":16},
{"base":"172.27.0.0/16","size":16},
{"base":"172.28.0.0/16","size":16},
{"base":"172.29.0.0/16","size":16},
{"base":"172.30.0.0/16","size":16},
{"base":"192.168.0.0/16","size":20}
]
}
설정이 끝났다면 iptables를 다시 실행한다.
httpd를 다시 실행해야 할 때
httpd 컨테이너를 재실행(restart)하지 않고도 설정 파일을 다시 적용(reload)하는 방법을 아직 찾지 못했다.
테스트 환경의 Alteon Switch에서 Layer 4 헬스체크가 잘 되는지 확인해 본다.
그러고는 s2 서버의 httpd 를 죽여본다.
FAILED 상태가 되고 트래픽을 보내지 않는다!
>> Server Load Balancing Information# /info/slb/virt 1
1: IP4 <vhost_IP_Address>, 00:00:00:00:00:00
virtual ports:
http: rport http, group 1, backup none, rtspslb none
real servers:
1: <s1_IP_Address>, backup none, 0 ms, group ena, up
2: <s2_IP_Address>, backup none, 0 ms, group ena, FAILED # HERE!
https: rport https, group 1, backup none, rtspslb none
real servers:
1: <s1_IP_Address>, backup none, 0 ms, group ena, up
2: <s2_IP_Address>, backup none, 0 ms, group ena, FAILED # HERE!
다시 httpd 를 살려본다.
up 상태가 되고 트래픽을 보낸다!
>> Server Load Balancing Information# /info/slb/virt 1
1: IP4 <vhost_IP_Address>, 00:00:00:00:00:00
virtual ports:
http: rport http, group 1, backup none, rtspslb none, slowstart
real servers:
1: <s1_IP_Address>, backup none, 0 ms, group ena, up
2: <s2_IP_Address>, backup none, 0 ms, group ena, up # HERE!
https: rport https, group 1, backup none, rtspslb none, slowstart
real servers:
1: <s1_IP_Address>, backup none, 0 ms, group ena, up
2: <s2_IP_Address>, backup none, 0 ms, group ena, up # HERE!
개선의 여지가 있다
아래에서 언급할 사항들은 위에서 도입한 기술과 별개로 기존에도 발생하던 문제다.
SessionRepositoryFilter 에러 페이지 응답
Tomcat Shutdown 직후 일시적으로 응답받을 수 있다. Graceful Shutdown, 요청 재시도(retry) 등을 고려해 볼 수 있다.
Type - Exception report
Message - Request processing failed; nested exception is java.lang.NullPointerException
Description - The server encountered an internal error that prevented it from fulfilling this request.
Exception
org.springframework.web.util.NestedServletException: Request processing failed; nested exception is java.lang.NullPointerException
...
org.springframework.web.filter.HttpPutFormContentFilter.doFilterInternal(HttpPutFormContentFilter.java:105)
...
org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:52)
org.apache.catalina.filters.HttpHeaderSecurityFilter.doFilter(HttpHeaderSecurityFilter.java:126)
org.springframework.security.web.FilterChainProxy$VirtualFilterChain.doFilter(FilterChainProxy.java:316)
...
Root Cause
java.lang.NullPointerException
org.springframework.session.web.http.SessionRepositoryFilter$SessionRepositoryRequestWrapper$SessionCommittingRequestDispatcher.forward(SessionRepositoryFilter.java:447)
...
Proxy
upstream 서버(Tomcat)의 응답이 늦어질 경우 발생할 수 있다.
mod_proxy 의 timeout 값을 조절하여 응답이 늦어지는 경우를 방지할 수 있다.
<!-- 502 Bad Gateway -->
Proxy Error
The proxy server received an invalid response from an upstream server.
The proxy server could not handle the request
Reason: Error reading from remote server
Akamai 에러 페이지 응답
Layer 4 Switch에서 1번 서버와 2번 서버 상태를 동시에 교체할 경우 응답받을 수 있다.
예를 들어, 1번 서버는 disable, 2번 서버는 enable 상태일 때
1번 서버를 enable, 2번 서버를 disable 상태로 변경한 후 apply 하면
다음과 같은 에러가 발생할 수 있다.
Service Unavailable - Zero size object
The server is temporarily unable to service your request. Please try again later.
Reference #15.6f4bc817.1651592357.1872133
2번 서버로 갔던 패킷이 갑자기 유실되면 CDN에서 받는 응답 데이터가 없어서 발생하는 것으로 추측하고 있다. 🤯
Akamai Reference에 따르면 #15.x.x.x는 ERR_ZERO_SIZE_OBJECT 에러다.
ERR_ZERO_SIZE_OBJECT— A response from the origin server has zero length.
Akamai에 문의 결과 해당 페이지는 커스텀 할 수 없다고 한다. 버려지는 요청들을 어떻게 처리할지 고민이 필요하다.
HAProxy 전환
이미 부분적으로 HAProxy를 사용해서 서비스를 이중화하고 있었다. HAProxy를 선택한 이유는 기본적으로 statistics 기능이 Web UI로 제공되면서 Layer 4, Layer 7 스위치로도 사용할 수 있다는 점이었다.
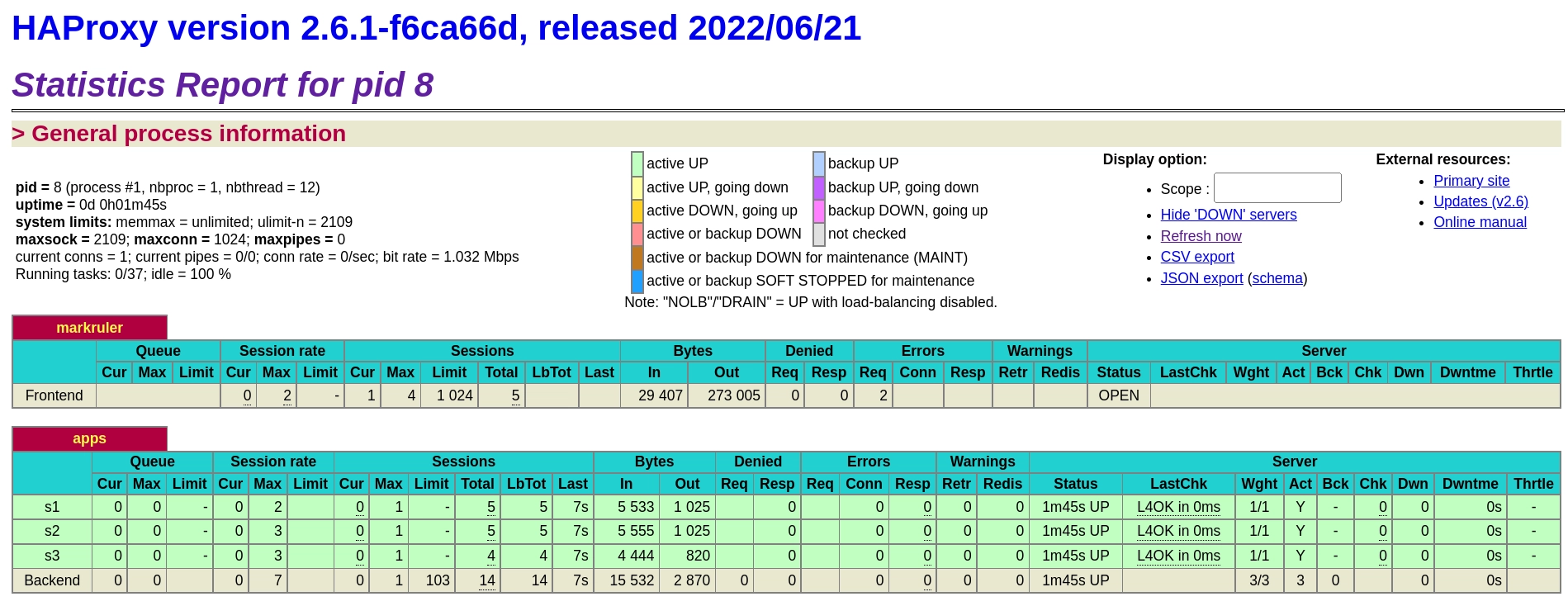
무엇보다도 XML 형식인 httpd 설정 파일에 비해 HAProxy의 설정 파일은 정말 간소하게 느껴졌기 때문에 전환하고 싶었다. 또한 가장 흔히 쓰는 것 같은 NGINX를 사용하지 않았던 이유는 가장 원했던 기능인 Active Healthcheck가 유료(NGINX Plus) 기능이기 때문이다.
선언형 배포 (GitOps?)
Bamboo에서는 Bamboo Specs라는 명칭으로 Infrastructure as Code(IaC)를 구현한다. — YAML Specs의 설정 파일에서는 SCP, SSH 등 주요 플러그인들을 지원하지 않기 때문에 Java Specs를 사용하는 것이 좋다.
# Task com.atlassian.bamboo.plugins.bamboo-scp-plugin:scptask is not supported yet
# Task com.atlassian.bamboo.plugins.bamboo-scp-plugin:sshtask is not supported yet
반면 Jenkins는 사용자가 많기 때문에 비교적 많은 플러그인을 지원하며 레퍼런스도 많다.
Jenkins Pipeline을 활용하면 Jenkinsfile 을 사용해서 선언형 배포 방식으로 쉽게 이전할 수도 있다.
그럼 빌드-배포 과정에서 발생할 수 있는 실수를 줄일 수 있고, 설정 정보를 버전 관리할 수 있다는 장점이 있다.
또한 Bamboo는 Slack으로 알림을 보내기 위해서는 Instant Message(IM) 서버가 필요하다. 반면 Jenkins는 Slack 연동 플러그인만 설치하면 쉽게 알림을 보낼 수 있다. 그럼 배포 작업은 단 1단계로 줄어든다. — 다만 기존에는 반영 사항을 공유할 때 Bamboo와 연동되어 있는 Jira 이슈만 간단히 캡처하면 됐지만, 아직 Jenkins와 Jira를 연동하지 못해서 어떻게 공유해야 할지 고민이 필요하다.
더 읽을 거리
- CI/CD
- CI/CD 정리 - markruler
- <지속적인 통합> 요약 - markruler
- 하루에 1000번 배포하는 조직 되기 - Banksalad
- Release Note 톺아보기 - kakao enterprise
- Proxy Server
- 포워드 프록시(forward proxy) 리버스 프록시(reverse proxy)의 차이 - lesstif
- Proxy servers explained - Cloudflare
- Reverse Proxy vs. Forward Proxy: The Differences - Oxylabs
- 포워드 프록시(forward proxy) 리버스 프록시(reverse proxy)의 차이 - lesstif
- SLB: Server Load Balancing
- Differences Between Layer 4 and Layer 7 Load Balancing - NGINX
- High Availability Load Balancers with Maglev - Cloudflare
- Multi-tier load-balancing with Linux - Vincent Bernat
- A Primer on Proxies - Cloudflare
- L4 vs L7 Load Balancing - Mohak Puri
- L4 & L7 - nowwater
- <인프라/네트워크 엔지니어를 위한 네트워크 이해 및 설계 가이드> - 미야타 히로시
- <인프라 엔지니어의 교과서: 네트워크 관리편> - 기술평론사 엮음
- <웹 엔지니어가 알아야 할 인프라의 기본> - 바바 토시아키
- L4 장비의 동작과 서비스 배포시 유의점 - Kakao
- L4 스위치 도입시 생겼던 이야기 - elky84
- Safe Deploy - 안전하게 L4 에서 제외하는 방법 - NHN
- L4/L7 스위치의 대안, 오픈 소스 로드 밸런서 HAProxy - NAVER D2
- Differences Between Layer 4 and Layer 7 Load Balancing - NGINX
- Docker
각주
-
<AWS 토폴로지로 이해하는 Amazon VPC> 10장. 분산 제어 - 차정도 ↩︎
최종 수정: 2022-08-17